




Data challenges créés pour 180 étudiants de
l'Université Paris-Saclay et l'Institut Polytechnique de Paris
Object Detection in Laser Wakefield Acceleration Simulations
En collaboration avec la Maison de la Simulation, CEA, Université Paris-Saclay
Ce challenge comptabilise 165 participants et a abouti à 294 soumissions
MAP estimation from non-invasive monitoring
En collaboration avec Inria, Université Paris-Saclay et l'AP-HP, Assistance Publique - Hôpitaux de Paris
Ce challenge comptabilise 169 participants et a abouti à 486 soumissions
Classification of variable stars from light curves
En collaboration avec le laboratoire IJCLab, Université Paris-Saclay
Ce challenge comptabilise 177 participants et a abouti à 1 223 soumissions

Challenge on single-cell type classification
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec le laboratoire MIA, Université Paris-Saclay.
Nicolas Jouvin (MIA Paris-Saclay, Associate Professor @ Univ. Paris-Saclay), François Caud (DATAIA, Univ. Paris-Saclay)
Data challenge créé pour le data-camp du Master 2 Data-Science de l'Université Évry (Paris-Saclay).
Ce challenge a réuni 26 participants et a abouti à 542 soumissions.
Biologiquement, il est connu que, bien que les cellules portent (presque) la même information génomique, elles ont tendance à n'exprimer qu'une fraction de leurs gènes, ce qui conduit à une spécialisation en types spécifiques avec des fonctions biologiques différentes. Ainsi, l'étude et la classification des types cellulaires sont d'un intérêt primordial pour de nombreuses applications biologiques et médicales. Au cours de la dernière décennie, il est devenu possible de mesurer le niveau d'expression des gènes à l'échelle d'une cellule unique grâce à l'essor des technologies à haut débit appelées RNA-seq de cellule unique (scRNA-seq).
Le but de ce défi de données est la classification supervisée des types cellulaires grâce au jeu de données de référence scMARK de Mendonca et al. Les auteurs ont compilé l'expression de 100 000 cellules issues de 10 études différentes afin de servir de comparaison pour diverses approches d'apprentissage automatique, en analogie avec le jeu de données de référence MNIST pour la vision par ordinateur.
Classification of patterns on extra solar hot Jupiter
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec la Maison de la Simulation, Université Paris-Saclay.
Martial Mancip (Maison de la Simulation, Saclay), François Caud, Thomas Moreau (DATAIA, Univ. Paris-Saclay)
Ce challenge a réuni 135 participants et a abouti à 403 soumissions.
Pour comprendre les résultats des récentes observations d'exoplanètes, les modèles basés sur la physique sont devenus de plus en plus complexes. Malheureusement, cela augmente à la fois le coût informatique et la taille des sorties de ces modèles. Nous avons l'intention d'explorer si la reconnaissance d'images par IA peut alléger ce fardeau. DYNAMICO a été utilisé pour exécuter une série de simulations similaires à HD209458 avec différents rayons orbitaux. Les simulations se répartissent en deux régimes : les simulations avec des rayons orbitaux plus courts présentent un mélange global important qui façonne la dynamique entière de l'atmosphère. En revanche, les simulations avec des rayons orbitaux plus longs montrent un mélange négligeable, sauf à des pressions intermédiaires. On pense que la classification d'images pourrait jouer un rôle important dans les futures études atmosphériques computationnelles. Cependant, une attention particulière doit être portée aux données alimentées dans le modèle, depuis la carte de couleurs jusqu'à l'entraînement du CNN sur des caractéristiques suffisamment larges et complexes pour que le CNN puisse apprendre à les détecter. Toutefois, en utilisant des études préliminaires et des modèles antérieurs, cela devrait être tout à fait réalisable pour les futurs calculs exascales, permettant ainsi une réduction significative des charges de travail et des ressources informatiques futures.
L'objectif de ce défi est de trouver des modèles d'apprentissage automatique capables de classifier ces motifs sur des images issues de simulations basées sur la physique.
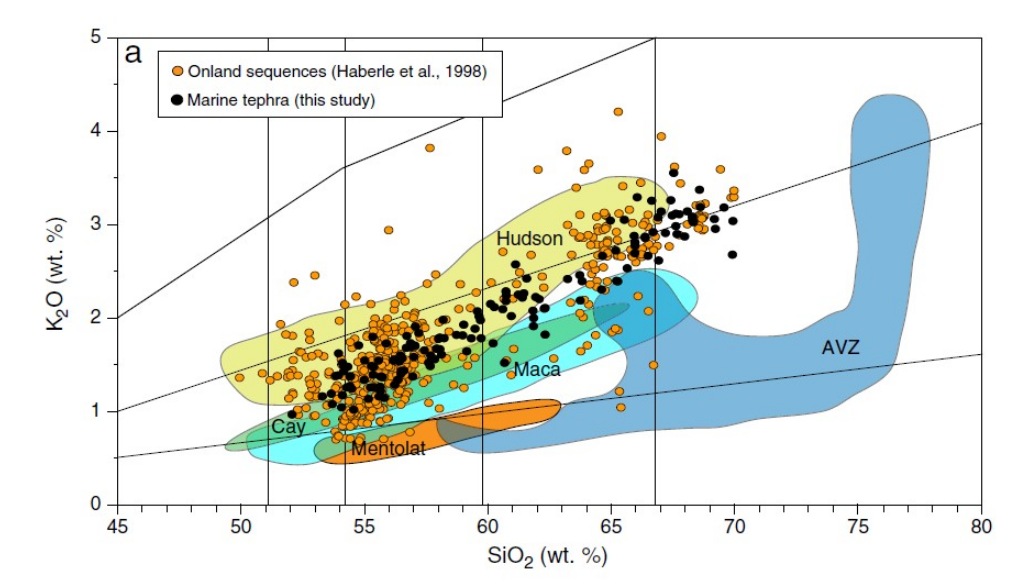
Volcanic events classification from tephras
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec le laboratoire GEOPS, Université Paris-Saclay.
Consuelo Martinez, Chiara Marmo, Guillaume Delpech (GEOPS, UPS), Marine Le Morvan, Thomas Moreau (Inria), François Caud (DATAIA, UPS)
Ce challenge a réuni 154 participants et a abouti à 2 601 soumissions.
La téphrochronologie est la discipline des géosciences qui utilise les dépôts des éruptions volcaniques explosives comme marqueurs stratigraphiques et chronologiques. En identifiant les restes pyroclastiques d'éruptions spécifiques (téphras) dans différents sites, la téphrochronologie aide à reconstituer l'histoire éruptive des centres volcaniques : l'ampleur de leurs éruptions, leur récurrence dans le temps et la dispersion de leurs produits. De plus, les téphras peuvent être considérés comme des points de repère stratigraphiques régionaux. Si un téphra spécifique est identifié dans différents archives paléoenvironnementales (par exemple, paléoclimatologiques, paléoocéanographiques, archéologiques), leurs chronologies peuvent être synchronisées, ce qui est essentiel pour interpréter l'évolution des systèmes complexes dans le temps, tels que le climat. L'objectif de ce défi de données est de prédire l'éruption volcanique (événement) en utilisant la composition géochimique des téphras.
ATLAS Stroke Lesion Segmentation
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec l'University of Southern California (USC).
Alexandre Hutton, Sook-Lei Liew (Neural Plasticity & Neurorehabilitation Lab, Univ. of Southern California), Maria Teleńczuk, Swetha Shanker, Guillaume Lemaitre, François Caud, Alexandre Gramfort (Université Paris-Saclay, Institut DATAIA)
L'accident vasculaire cérébral (AVC) est la principale cause de handicap chez l'adulte dans le monde, et jusqu'à deux tiers des personnes touchées souffrent d'un handicap à long terme. Des études de neuro-imagerie à grande échelle se sont révélées prometteuses pour l'identification de biomarqueurs robustes (par exemple, des mesures de la structure cérébrale) de la récupération de l'AVC à long terme après la rééducation. Cependant, l'analyse de grands ensembles de données liées à la réadaptation est problématique en raison des obstacles à la segmentation précise des lésions cérébrales. Les lésions tracées manuellement constituent actuellement l'étalon-or de la segmentation des lésions sur les IRM pondérées en T1, mais elles nécessitent une expertise anatomique et demandent beaucoup de travail. De plus, la segmentation manuelle est subjective, les évaluateurs produisant des résultats différents.
Bien que des algorithmes aient été développés pour automatiser ce processus, les masques de lésions qui en résultent manquent souvent de la précision nécessaire pour en faire des informations fiables. Les algorithmes plus récents qui utilisent des techniques d'apprentissage automatique et d'apprentissage profond sont des voies prometteuses, mais ils nécessitent des ensembles de données importants et diversifiés pour l'entraînement et le test et le développement de modèles généralisables. Dans le cadre de ce défi, l'entraînement peut être effectué sur notre jeu de données public ATLAS 2.0, et les tests sont réalisés avec un jeu de données multi-sites provenant des mêmes sites qu'ATLAS 2.0.
Brain age prediction and debiasing with site-effect removal in MRI through representation learning
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec le CEA NeuroSpin.
Antoine Grigis, Benoît Dufumier, Edouard Duchesnay (Université Paris-Saclay, CEA, NeuroSpin), François Caud, Alexandre Gramfort (Université Paris-Saclay, DATAIA)
La modélisation du développement et de la maturation du cerveau dans la population saine à l'aide du Machine Learning (ML) à partir d'images IRM du cerveau est un défi fondamental. Les processus biologiques impliqués sont complexes et très hétérogènes entre les individus, comprenant à la fois une variabilité environnementale et génétique entre les sujets. Par conséquent, il est nécessaire de disposer de grands ensembles de données IRM comprenant des sujets d'âges très divers. Cependant, ces ensembles de données sont souvent multi-sites (c'est-à-dire que les images sont acquises dans différents hôpitaux ou centres d'acquisition à travers le monde) et cela induit un fort biais dans les données IRM actuelles, en raison des différences entre les scanners (champ magnétique, constructeur, gradients, etc.).
Par conséquent, ce défi vise à construire i) des modèles ML robustes qui peuvent prédire avec précision l'âge chronologique à partir de l'IRM du cerveau tout en ii) éliminant les informations non biologiques des images IRM. Nous avons conçu ce défi dans le contexte de l'apprentissage par représentation et il encourage le développement de nouveaux algorithmes de ML et de Deep Learning.
Plus précisément, le vieillissement est associé à l'atrophie de la matière grise (MG). Chaque année, un adulte perd 0,1% de sa MG. Nous allons essayer d'apprendre un prédicteur de l'âge chronologique (âge réel) en utilisant des caractéristiques dérivées de la MG sur une population de participants témoins en bonne santé. Un tel prédicteur fournit l'âge cérébral attendu d'un sujet. Une déviation de cet âge cérébral attendu indique une accélération ou un ralentissement du processus de vieillissement qui peut être associé à un processus neurobiologique pathologique ou à un facteur de protection du vieillissement. Le jeu de données est composé d'images provenant de divers sites, de différents scanners IRM et acquises dans des conditions variées. Afin de prédire correctement l'âge des participants, il faut tenir compte de l'effet site/scanner.
Bovine embryos survival prediction
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec l'Institut National de Recherche pour l'Agriculture, l'Alimentation et l'Environnement (INRAE) et l'École Nationale Vétérinaire d'Alfort (ENVA).
Julien Chiquet (MIA Paris-Saclay, Inrae), Pierre Gloaguen (MIA Paris-Saclay, AgroParisTech), Nicolas Jouvin (MIA Paris-Saclay), Patrick Bouthemy (SERPICO, Inria), Alain Truibil (MaiAGE, Inrae), Alline Reis (PASP, ENVA), François Caud, Alexandre Gramfort (DATAIA, Univ. Paris-Saclay)
Ce défi consiste à prédire l'état de développement des embryons bovins vus à 8 jours après la fécondation (daf). Il existe 8 classes différentes (notées de "A" à "H" dans ce défi) correspondant à des états biologiques allant de vivant ("A") à mort ("H"). Les étiquettes connues sont l'état de développement des embryons à 8 daf, cependant, il est très intéressant de pouvoir prédire cet état futur le plus tôt possible. Le but de ce défi est de prédire ces états entre 1 et 4 daf (au plus tard) et d'être le plus précis possible par rapport aux étiquettes indiquées. Pour cela, vous avez accès à 277 vidéos issues de notre propre base de données (INRAE), chacune composée de 300 instantanés pris toutes les quinze minutes.
Predict schizophrenia using brain anatomy (classification)
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec le CEA NeuroSpin.
Edouard Duchesnay, Antoine Grigis, Benoît Dufumier (Université Paris-Saclay, CEA, NeuroSpin), François Caud, Alexandre Gramfort (Université Paris-Saclay, DATAIA)
Prédire la schizophrénie à partir de la matière grise du cerveau. La schizophrénie est associée à un schéma diffus et complexe d'atrophie du cerveau. Nous allons essayer d'apprendre un prédicteur de l'état clinique (patient atteint de schizophrénie vs contrôle sain) en utilisant les mesures de la matière grise sur les participants du cerveau.
Prediction of the isotopic inventory in a nuclear reactor core
Ce défi, organisé en août 2021, a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec l'Institut de Radioprotection et de Sûreté Nucléaire (IRSN).
Benjamin Dechenaux, Jean-Baptiste Clavel, Cécilia Damon (IRSN), François Caud, Alexandre Gramfort (DATAIA, Univ. Paris-Saclay)
Ce challenge a réuni 98 participants et a abouti à 976 soumissions.
La matière contenue dans un réacteur nucléaire subit une irradiation qui provoque des cascades successives de réactions nucléaires, modifiant sa composition atomique. La connaissance de cette composition évoluant dans le temps est un paramètre important utilisé pour modéliser le comportement d'un réacteur nucléaire. Mais c'est aussi un élément crucial pour les études de sûreté liées à son fonctionnement et un élément clé pour l'atténuation d'un accident grave. Connaître à un instant donné la composition d'un réacteur permet d'évaluer rapidement quels isotopes radioactifs peuvent être libérés dans l'environnement. La modélisation de l'évolution de la composition atomique des matériaux irradiés au fil du temps est généralement réalisée à l'aide de simulations Monte Carlo du système étudié, qui sont coûteuses en temps. Bien que précis, ce schéma de calcul peut s'avérer inadapté dans des situations de crise (c'est-à-dire accidentelles), où des schémas de calcul plus rapides doivent être développés. Ce projet vise à construire un modèle par apprentissage automatique capable de prédire l'évolution de l'inventaire nucléaire d'un réacteur typique de la flotte française.
Detection and classification of ovarian follicles
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec INRIA, CNRS, INSERM et INRAE.
Frédérique Clément (INRIA), Raphäel Corre (CNRS), Céline Guigon (INSERM), François Caud, Benjamin Habert, Alexandre Gramfort (DATAIA, Univ. Paris-Saclay)
Ce challenge a réuni 82 participants et a abouti à 409 soumissions.
Le défi consiste à détecter et à classer automatiquement les follicules ovariens sur des coupes histologiques d'ovaires de mammifères. L'ovaire est un exemple unique d'organe endocrine dynamique, en remodelage permanent à l'âge adulte. La fonction ovarienne est soutenue par des structures sphéroïdes, multicouches et multiphasiques, les follicules ovariens, qui abritent l'ovocyte (cellule germinale femelle) et sécrètent une variété d'hormones et de facteurs de croissance. L'ovaire est doté d'un pool de follicules établi tôt dans la vie, qui s'épuise progressivement par le développement ou la mort des follicules. La compréhension de la dynamique des populations de follicules ovariens est essentielle pour caractériser le statut physiologique reproducteur des femelles, de la naissance (voire de la vie prénatale) à la sénescence reproductive.
L'estimation précise du nombre de follicules ovariens à différents stades de développement est d'une importance capitale dans le domaine de la biologie de la reproduction, pour la recherche fondamentale, les études pharmacologiques et toxicologiques, ainsi que pour la gestion clinique de la fertilité. Les défis sociétaux associés concernent le vieillissement ovarien physiologique (diminution de la fertilité avec l'âge, ménopause), le vieillissement pathologique (insuffisance ovarienne prématurée) et le vieillissement induit par des composants toxiques (perturbateurs endocriniens, traitements anticancéreux). In vivo, seuls les stades terminaux des follicules, donc la partie émergée de l'iceberg, peuvent être suivis par échographie. Pour détecter tous les follicules, des approches invasives, reposant sur l'histologie, sont nécessaires. Les ovaires sont fixés, coupés en série et teintés avec des colorants appropriés, puis analysés manuellement par microscopie optique. Un tel comptage est une procédure complexe, fastidieuse, dépendante de l'opérateur et, surtout, très chronophage. Pour gagner du temps, seules quelques tranches prélevées sur un ovaire entier sont examinées, ce qui ajoute au bruit expérimental et dégrade encore la fiabilité des mesures. Les expérimentateurs attendent beaucoup de l'amélioration de la procédure de comptage classique, et les approches du comptage folliculaire basées sur l'apprentissage profond pourraient apporter une avancée considérable dans le domaine de la biologie de la reproduction.
Nous distinguerons ici 4 catégories de follicules, des plus petits aux plus grands : primordial, primaire, secondaire et tertiaire. L'une des difficultés réside dans le fait qu'il existe une grande disparité de taille entre tous les follicules. Une autre difficulté est que la plupart des modèles de classification pré-entraînés, le sont sur des objets de la vie quotidienne et non sur des tissus biologiques.
Predict age from brain grey matter (regression)
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec le CEA NeuroSpin.
Edouard Duchesnay, Antoine Grigis (Université Paris-Saclay, CEA, NeuroSpin), François Caud, Alexandre Gramfort (Université Paris-Saclay, Institut DATAIA)
Ce challenge a réuni 31 participants et a abouti à 334 soumissions.
Ce défi consiste à prédire l'âge d'un individu à partir de la quantité de matière grise du cerveau (régression). Le vieillissement est associé à une atrophie de la matière grise (MG). Chaque année, un adulte perd 0,1% de MG. Nous allons essayer d'apprendre un prédicteur de l'âge chronologique (âge réel) en utilisant des mesures de MG sur le cerveau sur une population de participants témoins sains. Un tel prédicteur fournit l'âge cérébral attendu d'un sujet. Une déviation de cet âge cérébral attendu indique une accélération ou un ralentissement du processus de vieillissement qui peut être associé à un processus neurobiologique pathologique ou à un facteur de protection du vieillissement.
Brain age regression with deep learning
Ce défi a été réalisé avec le soutien de l'Institut DATAIA, en collaboration avec le CEA NeuroSpin.
Edouard Duchesnay, Antoine Grigis (Université Paris-Saclay, CEA, NeuroSpin), François Caud, Alexandre Gramfort (Université Paris-Saclay, Institut DATAIA)
Le challenge brainage_deep est une extension du précédent challenge (brain age), permettant la soumission de réseaux de neurones profonds.
-
Imaging-psychatry challenge
L'IMPAC (IMaging-PsychAtry Challenge) est un défi de données sur les troubles du spectre autistique (TSA). Les TSA sont des troubles psychiatriques graves qui touchent 1 enfant sur 166. Il existe des preuves que les TSA se reflètent dans les réseaux neuronaux et l'anatomie du cerveau des individus. Pourtant, on ne sait toujours pas dans quelle mesure ces effets sont systématiques, ni quelle est l'ampleur de leur prédiction. La grande cohorte réunie ici peut apporter quelques réponses. La prédiction de l'autisme à partir de l'imagerie cérébrale fournira des biomarqueurs et éclairera les mécanismes de la pathologie.
-
Juillet : Mars crater detection
Ce défi propose de concevoir, à l'aide d'une stratégie de collaboration, le meilleur algorithme utilisant une stratégie de collaboration pour détecter la position et la taille des cratères à partir de la base de données la plus complète de cratères martiens contenant 384 584 structures d'impact vérifiées de plus d'un kilomètre de diamètre. Nous proposons de donner aux utilisateurs un sous-ensemble de ce grand ensemble de données afin de tester et de calibrer leur algorithme. Nous fournissons un jeu de données nocturnes THEMIS, déjà projeté pour éviter toute distorsion, échantillonné à différentes échelles et positions sous forme d'images de 112×112 pixels. En utilisant une métrique appropriée, nous comparerons la solution réelle à l'estimation. L'objectif est de fournir une détection de plus de 90% (centre et diamètre du cratère) avec un nombre minimum de mauvaises détections.
-
Février : Macroeconomic surrogate
Dans le RAMP Macroeconomic Surrogate, nous avons appris un modèle de substitution pour un modèle macroéconomique basé sur des agents (ABM) et une fonction objective. L'objectif était d'avoir un algorithme de filtrage rapide qui peut remplacer cette simulation plus lente dans, par exemple, une optimisation stochastique ou un calcul bayésien approximatif. L'évènement a eu lieu le février 2016 à la Maison des Sciences Économiques.
-
Mai : HEP detector anomalies
L'objectif du RAMP de l'Atlas du LHC était de détecter des anomalies dans le détecteur Atlas du LHC, de séparer un point de données biaisé d'un point de données original. L'évènement a eu lieu en mai 2016 à l'Auditorium Pierre Lehmann (LAL).
-
Mai : Drug classification for Spectra
La chimiothérapie est l'un des traitements les plus utilisés contre le cancer. Pour éviter les erreurs de médication, certaines réglementations françaises récentes imposent la vérification des médicaments anticancéreux avant leur administration. Dans ce contexte, l'objectif du RAMP sur la classification des médicaments était de développer des modèles de prédiction capables d'identifier et de quantifier les agents chimiothérapeutiques à partir de leurs spectres Raman. L'évènement a eu lieu en mai 2016 au PROTO204.
-
Janvier : HiggsML
Le RAMP HiggsML était le premier événement d'une série de bootcamps que le CDS lançait. Cette première session consistait en une introduction douce à l'apprentissage automatique pratique par le biais d'une application concrète aux données du défi Higgs-ML (expérience ATLAS). L'événement a eu lieu à PROTO204 en janvier 2015 et nous avions un invité spécial, Gábor Melis, qui a récemment remporté le concours Higgs-ML organisé par Kaggle.com.
-
Février : Health care
Le RAMP sur les soins de santé a eu lieu en février 2015 au PROTO204 et il s'agissait de la deuxième édition des bootcamps du CDS en apprentissage automatique et en science des données.
-
Avril : Classification des étoiles variables
Le RAMP Classification des étoiles variables a eu lieu à PROTO204 en avril 2015 et portait sur l'astrophysique, plus précisément sur la classification des étoiles variables à partir de leurs courbes de lumière (profils de luminosité en fonction du temps).
-
Juin : El Niño prediction
De même que pour le RAMP sur les étoiles variables, dans le RAMP sur la prédiction d'El Niño, le pipeline était constitué d'un extracteur de caractéristiques et d'un prédicteur. Ce RAMP a eu lieu au PROTO204 en juin 2015, et son objectif était de prédire six mois à l'avance la température de surface (TAS) dans la région El Niño 3.4 à partir des données TAS simulées par le modèle CCSM4.
-
Octobre : Pollenating insects
Le RAMP sur les insectes pollinisateurs a eu lieu au PROTO204 en octobre 2015. Dans ce RAMP, nous avons classé des images d'insectes pollinisateurs issues du projet de crowdsourcing SPIPOLL du Muséum d'histoire naturelle de Paris (MNHN). Ce RAMP vous est présenté par Romain Julliard (MNHN) et vos coachs habituels. Nous remercions le Centre HPC ROMEO de l'Université de Champagne-Ardenne et NVIDIA pour avoir fourni le backend GPU et le support technique pour le RAMP, ainsi que Proto204 pour avoir accueilli l'événement.
![[PARTNERSHIP] Scienta Lab x DataIA-Cluster to advance multimodal and explainable AI research](/sites/default/files/styles/vue_min/public/2025-04/og-image.webp?itok=D0mXTN-r)

