




Nous sommes ravis d'annoncer la sortie de Tower, un grand modèle de langage (LLM) multilingue de 7B paramètres optimisé pour les tâches liées à la traduction. Tower est construit sur LLaMA2 [1] et supporte actuellement 10 langues : anglais, allemand, français, espagnol, chinois, portugais, italien, russe, coréen et néerlandais. Il correspond aux modèles de pointe en matière de traduction, ainsi qu'à GPT3.5, et surpasse des modèles ouverts plus importants, tels qu'ALMA 13B [5] et LLaMA-2 70B. Tower maîtrise également un certain nombre d'autres tâches liées à la traduction, allant des tâches de pré-traduction, telles que la correction d'erreurs grammaticales, aux tâches de traduction et d'évaluation, telles que la traduction automatique (TA), la post-édition automatique (APE) et le classement des traductions. Si vous travaillez sur le NLP multilingue et les problèmes connexes, n'hésitez pas à essayer Tower.
La formation et la publication du modèle Tower sont le fruit d'un effort conjoint d'Unbabel, du laboratoire SARDINE de l'Instituto Superior Técnico et du laboratoire MICS de CentraleSupélec de l'Université Paris-Saclay. L'objectif de cette version est de promouvoir la recherche collaborative et reproductible afin de faciliter le partage des connaissances et de faire progresser les LLM multilingues et la recherche connexe. À ce titre, nous sommes heureux de :
-
publier les poids de nos deux modèles Tower : TowerBase et TowerInstruct
-
publier les données que nous avons utilisées pour affiner ces modèles : TowerBlocks
-
libérer les données et le code d'évaluation : TowerEval, le premier référentiel d'évaluation LLM pour les tâches liées à la MT
De LLaMA2 à Tower : comment nous avons transformé un LLM centré sur l'anglais en un LLM multilingue
L'année dernière, les grands modèles de langage ont pris le monde d'assaut. De GPT-3.5 à LLaMA et Mixtral, les LLM fermés et open-source ont démontré des capacités de plus en plus fortes pour résoudre des tâches de langage naturel. La traduction automatique ne fait pas exception : GPT-4 figurait parmi les meilleurs systèmes de traduction de l'année dernière pour plusieurs directions linguistiques dans le cadre de la piste de traduction générale du WMT2023, la référence la plus établie dans ce domaine.
Malheureusement, l'histoire n'est pas la même avec les modèles open-source actuels ; ils sont principalement construits avec des données anglaises et peu ou pas de données multilingues et doivent encore faire une percée significative dans la traduction et les tâches connexes, comme la post-édition automatique, l'évaluation automatique de la traduction, entre autres. Nous devions combler cette lacune et nous avons donc entrepris de construire un modèle multilingue de pointe à partir de LLaMA2.
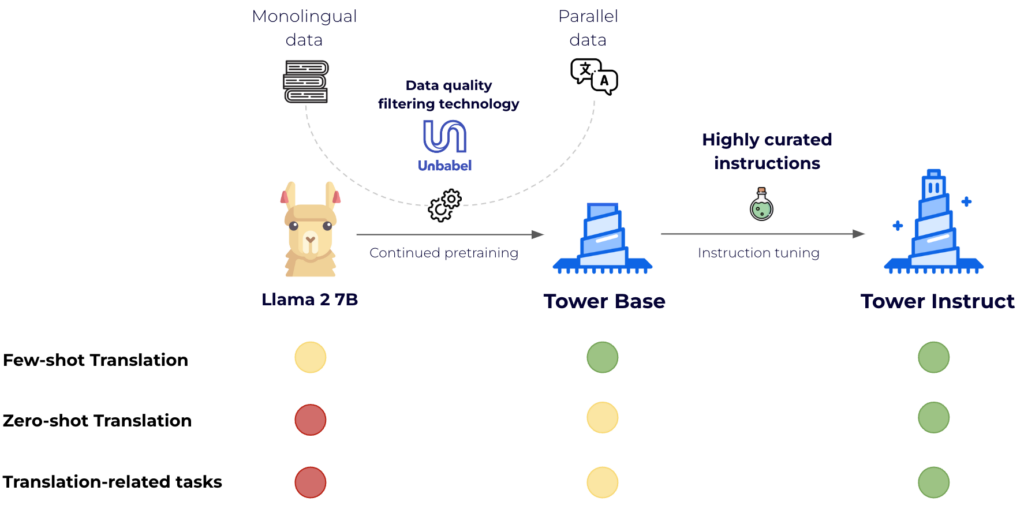
Cela a nécessité deux étapes : un pré-entraînement continu et un réglage des instructions. La première est essentielle pour améliorer le support de LLaMA2 pour d'autres langues, et la seconde fait passer le modèle au niveau supérieur en termes de résolution de tâches spécifiques d'une manière 0-shot.
Pour le pré-entraînement continu, nous avons utilisé 20 milliards de tokens de texte répartis de manière égale entre les langues. Deux tiers des tokens proviennent de sources de données monolingues - une version filtrée de l'ensemble de données mc4 [3] - et un tiers est constitué de phrases parallèles provenant de diverses sources publiques telles que OPUS [5]. Nous nous appuyons sur la technologie Unbabel, COMETKiwi [2], pour filtrer les données parallèles de haute qualité. Le résultat est une version considérablement améliorée de LLaMA2 pour les langues cibles qui conserve ses capacités en anglais : TowerBase. Les langues supportées par la version actuelle sont l'anglais, l'allemand, le français, le chinois, l'espagnol, le portugais, l'italien, le néerlandais, le coréen et le russe.
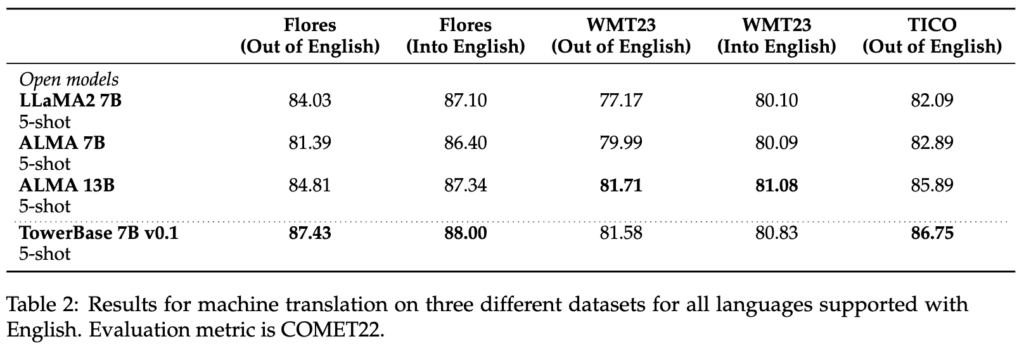
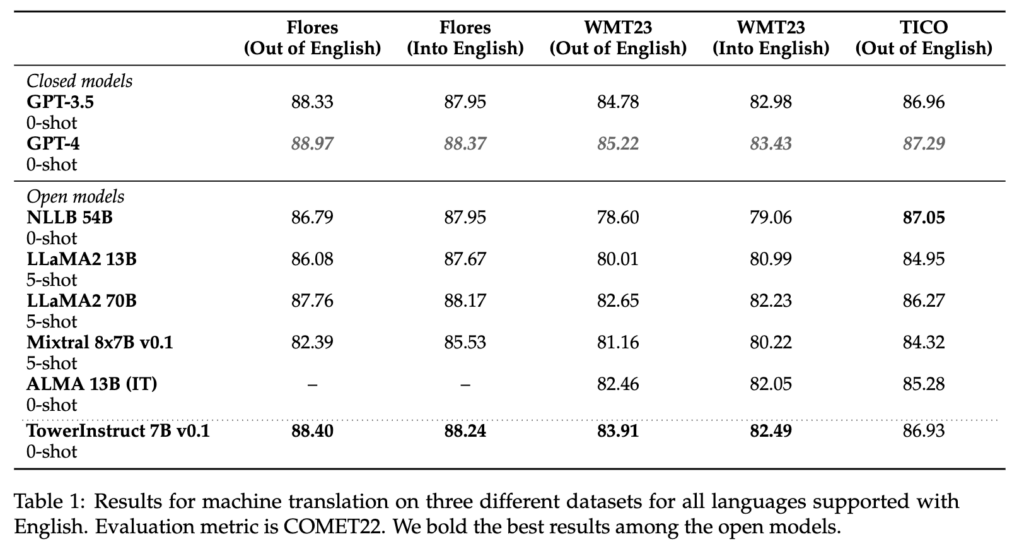
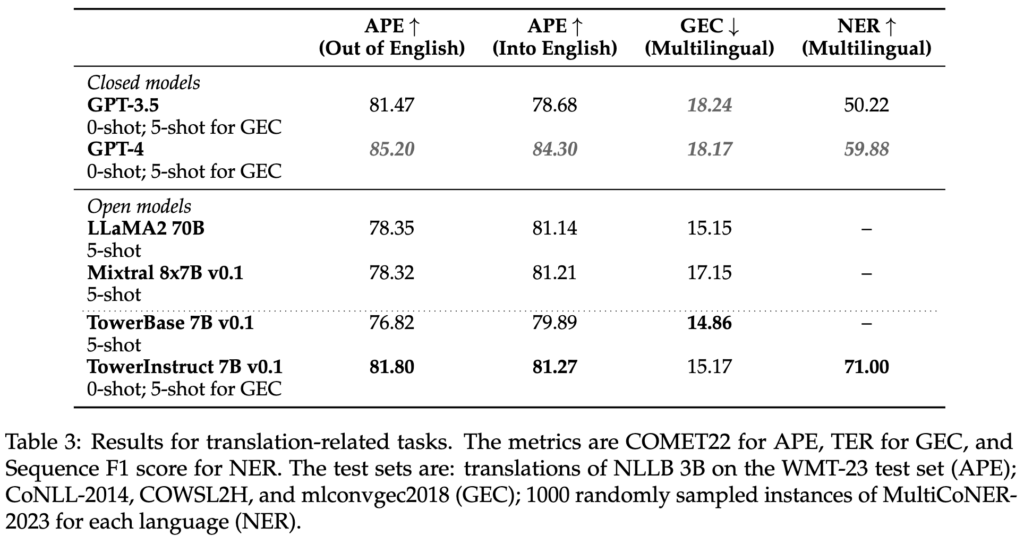
Pour la mise au point supervisée, nous avons soigneusement construit un ensemble de données avec divers enregistrements de haute qualité spécifiques aux tâches, ainsi que des données conversationnelles et des instructions de code. Nous avons construit manuellement des centaines d'invites différentes pour toutes les tâches, y compris des modèles de zéro et de quelques secondes. Notre ensemble de données, TowerBlocks, comprend des données relatives à de nombreuses tâches liées à la traduction, telles que l'édition automatique de messages, la traduction automatique et ses différentes variantes (par exemple, la traduction tenant compte du contexte, la traduction tenant compte de la terminologie, la traduction multiréférentielle), la reconnaissance des entités nommées, la prédiction de l'étendue des erreurs, la génération de paraphrases, et d'autres encore. Les enregistrements de données ont été soigneusement filtrés à l'aide de différentes heuristiques et de filtres de qualité, tels que COMETKiwi, afin de garantir l'utilisation de données de haute qualité au moment de la mise au point. Plus que tout autre facteur, ce filtrage, combiné à un choix judicieux des hyperparamètres, a joué un rôle crucial dans l'obtention d'améliorations significatives par rapport au modèle pré-entraîné continu. Le modèle qui en résulte, TowerInstruct, traite plusieurs tâches de manière transparente en mode 0-shot - améliorant l'efficacité au moment de l'inférence - et peut résoudre d'autres tâches en suspens avec une ingénierie prompte appropriée. En particulier, pour la traduction automatique, TowerInstruct est compétitif et peut surpasser GPT3.5 et Mixtral 8x7B [6], tandis que pour la post-édition automatique, la reconnaissance des entités nommées et la correction des erreurs de source, il surpasse GPT3.5 et Mixtral 8x7B sur toute la ligne, et peut même aller jusqu'à surpasser GPT4.
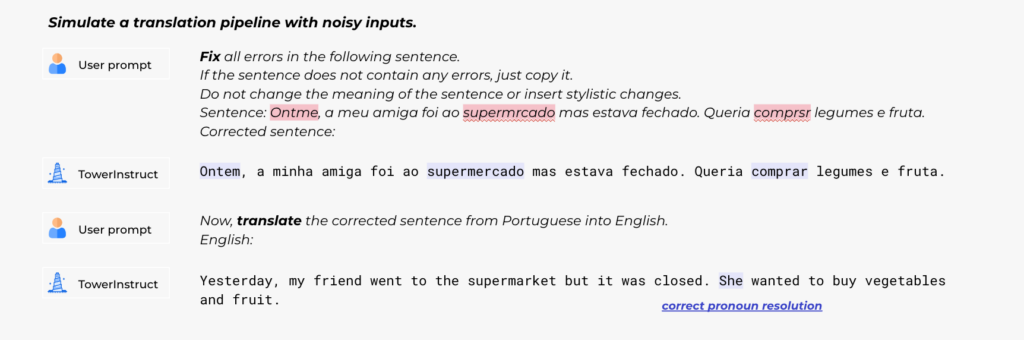


Utilisation des modèles Tower
Nous publions les poids des modèles pré-entraînés et adaptés aux instructions, ainsi que les données d'adaptation et d'évaluation des instructions. Nous publierons également TowerEval, un référentiel d'évaluation axé sur la TA et les tâches connexes, qui permettra aux utilisateurs de reproduire nos benchmarks et d'évaluer leurs propres LLM. Nous vous invitons à visiter notre page Huggingface et notre dépôt GitHub et à commencer à les utiliser !
Ces modèles Tower ne sont qu'un début : en interne, nous travaillons sur l'exploitation de la technologie et des données d'Unbabel pour améliorer notre plateforme de traduction. À l'avenir, nous prévoyons des versions encore plus intéressantes, alors restez à l'écoute !
Remerciements
Une partie de ce travail a été soutenue par les actions de recherche et d'innovation Horizon Europe de l'UE (UTTER, contrat 101070631), par le projet DECOLLAGE (ERC-2022-CoG 101088763), et par le plan de relance et de résilience portugais à travers le projet C645008882- 00000055 (Center for Responsible AI). Nous remercions GENCI-IDRIS pour le support technique et les ressources HPC utilisées pour soutenir partiellement ce travail.
Références
[1] Llama 2: Open Foundation and Fine-Tuned Chat Models. Technical report
[2] Scaling up CometKiwi: Unbabel-IST 2023 Submission for the Quality Estimation Shared Task. WMT23
[3] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
[4] Parallel Data, Tools and Interfaces in OPUS. LREC2012
[5] A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models
[6] Mixtral of Experts


